Making deployments boring with CloudFormation or Terraform
CloudFormation and Terraform are both tools to describe your infrastructure as code. They enable us to easily provision, re-provision and update our infrastructure without losing control of all the changes. I’ve used both tools many times in different products, and I was never in a situation that either tools let me down. That being said both tools have strengths and weaknesses. On the one hand, Terraform configuration files tend to be more concise and readable, on the other hand CloudFormation offers better support for rotating servers. In this blog post, I am going to show you how you can use CloudFormation or Terraform for this job and what are the trade-offs of each tool.
I have been thinking recently about the role those tools play in our Continuous Delivery pipelines. Beyond setting up VPCs, databases and configuring DNS entries you can use either tool to deploy your application by replacing your servers with new ones that run the newer version of your application.
Let’s set the Stage
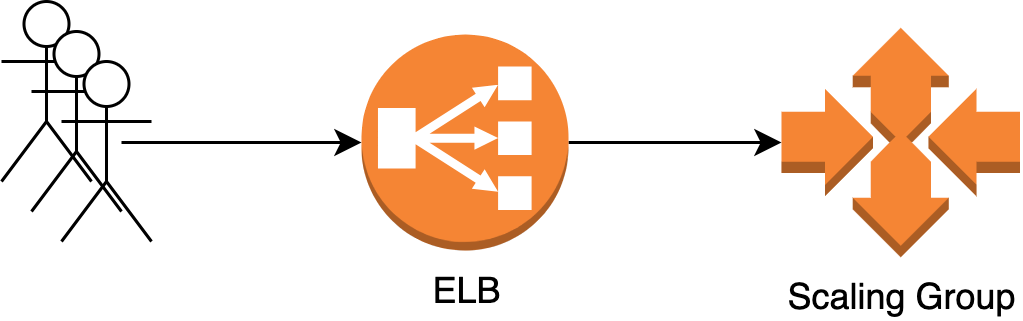
Let’s say you have a cloud deployment in AWS, your servers are happily chugging along serving requests behind a load balancer. You’ve put your servers in a scaling group to easily scale them in and out.
Since development never ends, the time comes to deploy a newer version of your application. You want your deployment to be a non-event, a boring automated process that just gets you to the newer version. Moreover, if something goes wrong you want the tool to notice and give you visibility in the pipeline.
As an example, let’s say that you have a springboot application, which your pipeline builds and tests. The artifacts (a .jar in our case) are versioned and pushed in an S3 bucket. The last step of your pipeline is to invoke either Terraform or CloudFormation passing the latest version number and let the tool deploy production for you.
Deploying with Terraform
Terraform is a tool developed by HashiCorp, it can do a lot more than just AWS but in our case we only use the AWS integration. Let’s say you have provisioned the infrastructure described about with Terraform. That means you have a configuration file written in the Hashicorp Configuration Language (HCL) containing something similar to this:
resource "aws_launch_configuration" "lc" {
name_prefix = "lc"
image_id = var.ami_id
instance_type = "t3.micro"
user_data = data.template_file.template.rendered
lifecycle {
create_before_destroy = true
}
}
resource "aws_autoscaling_group" "application-servers" {
name_prefix = "app-${aws_launch_configuration.lc.id}-"
launch_configuration = aws_launch_configuration.lc.id
max_size = var.instance_count
min_size = var.instance_count
health_check_type = "ELB"
load_balancers = [aws_elb.elb.id]
min_elb_capacity = var.instance_count
lifecycle {
create_before_destroy = true
}
}
The above code describes a launch configuration and a scaling group. Roughly speaking, the launch configuration describes the properties of each individual instance of the group whereas the scaling group the properties of the whole group.
The two resources above reference other resources that are not visible in the example:
-
ELB: The Elastic Load Balancer is the known stable entry point to your service. It provides one Domain Name that remains unchanged no matter how many instances your service has nor how often you redeploy.
-
User Data: The user data describe an initial set of instructions to be executed on each instance of your service on boot up. In our example, they download the latest jar for the artifact store and spin it up.
Terraform zero downtime deployment
Terraform operates by comparing the ideal state as described to the file above with the actual state of your infrastructure and then takes actions to reconcile them if it’s necessary. In our case, the user data section changes since it references the version number which increases from release to release. Terraform resolves that since the user data has changed the launch configuration also needs to be replaced. And there it stops, it does not mark the auto scaling group (which controls the actual running servers) as something that also needs to change.
To instruct terraform to replace the auto scaling group you need to make the auto scaling group’s name dependent to the launch configuration. Moreover, you need to tell terraform to bring the new auto scaling group up before terminating the old one, otherwise your users will experience downtime. You do that by setting the create_before_destroy option to true. You also need to set the min_elb_capacity so that Terraform will wait for the new instances to register to the load balancer before starting to terminate old instances.
Waiting for the new instances to register with the load balancer (combined with a robust health check) means that if the new version is dead on arrival the old version will remain active, and your users will not experience any outage. Definitely a good thing!
Deploying with Cloudformation
CloudFormation is the AWS solution to infrastructure automation. It is a managed serviced offered for free to manage AWS infrastructure.
Let’s see how the above example would look like as a CloudFormation template:
LaunchConfig:
Type: AWS::AutoScaling::LaunchConfiguration
Properties:
ImageId:
Ref: "ImageId"
InstanceType:
Ref: "InstanceType"
UserData:
Fn::Base64:
Ref: "UserData"
WebServerGroup:
Type: AWS::AutoScaling::AutoScalingGroup
UpdatePolicy:
AutoScalingRollingUpdate:
MinInstancesInService : 1
MaxBatchSize : 1
Properties:
AvailabilityZones:
Fn::GetAZs: ""
LaunchConfigurationName:
Ref: "LaunchConfig"
LoadBalancerNames:
- Ref: "ElasticLoadBalancer"
MinSize:
Ref: "MinSize"
MaxSize:
Ref: "MaxSize"
Cloudformation templates are written in YAML or JSON. The example above is in YAML. The CF and the TF examples are extremely similar. Both of them create a launch configuration, and an auto scaling group, even the parameters are pretty much the same, that stems from the fact that they both need to call to the AWS API.
Just looking at the two examples, I believe it is easy to see that the HCL configuration (Terraform) is a lot more readable. That is definitely one the weak points of CloudFormation.
CloudFormation zero downtime deployment
Now to the task at hand, how can CloudFormation make deployments simple and boring?
If you look more carefully in the auto scaling group will see a section called UpdatePolicy. In that section we instruct CF how to update our servers, namely it should replace the old servers one by one with new ones. It is that simple! Again CloudFormation will make sure that the new servers are up and running before shutting down the old ones.
Cloudformation does not need to replace the auto scaling group because it can do a rolling update within the same scaling group. Just by maintaining the auto scaling group means that you don’t lose visibility of the monitoring metrics and that the resource names remain short and readable.
Definitely the major advantage of CloudFormation over Terraform for CI/CD is that CloudFormation supports rollbacks, which means that in case something is wrong with the new version CF will automatically return to the previous version and neatly clean up any stale resources. No need for human intervention.
Caveats
Terraform
Zero downtime deployments with Terraform are certainly possible but here are some things that I found less nice.
Most problems arise from the fact that if something goes wrong Terraform will just quit without cleaning up. That means your prod is now in limbo containing a some mix of old and new resources.
I have experience terraform leaving behind auto scaling group and launch configuration resources. That may not seem as important until a future deployment fails randomly because you reached the limit in one of those resources.
Sometimes, the new scaling will keep spinning up instance in perpetuity, which they then fail to register with the ELB and get terminated. Still, nothing that your users will notice, but it will cost you money and will not stop until you manually intervene.
One of the most insidious cases is when the deployment fails after the new auto scaling group is registered with the ELB but before the old one in retired. In that case, your users will interact randomly by either the new version or the old version of your application.
There are also some smaller issues which although not critical I found annoying. Since during the deployment you are going to have two auto scaling groups and two launch configuration Terraform tries to avoid resource name conflicts by appending a long string of numbers after the name of each resource, which make the names hard to read and hard to distinguish from one another.
Another annoyance is that CloudWatch monitoring gets more difficult, since the monitoring data is grouped by scaling group, every time there is a deployment you lose easy access to the monitoring data from before the deployment.
All in all, a deployment gone wrong with Terraform will probably require manual intervention to clean up.
CloudFormation
The rollback functionality that CloudFormation is offering can help automate that last step of your pipeline. Even though rollbacks work reliably when it comes to auto-scaling groups and launch configuration, I must warn you that rollbacks can still fail especially when used to deploy other resource like RDS or VPC. It is definitely important to know that, but in my experience the application changes a lot more often than the infrastructure around it thus it is still a very helpful feature.
Conclusion
At this blog post, I show how to use CloudFormation and Terraform to solve one of the most common tasks of Continuous Delivery namely deploying to production. I know that both tools have a lot more use cases and especially Terraform. My goal is not to extensively compare the two, but rather to explain how they fit in your pipelines.
Edited by Mike Winter