Simplify planning and forecasting with Python and statistics
In my previous posts Sprint velocity, what is it good for? and Better sprint planning with Bayes, I talked about using statistics for more reliable forecasting and for quantifying uncertainty. In this post, I want to show you the code to automate the process, so that us humans can focus on making decisions based on the data.
I am going to use Python for this example, because it has great libraries for data science and statistics.
I am going to use numpy and scipy.
Getting the data
You need data for your past velocity and information about the milestone you wish to achieve (how many sprints have left and how many stories).
For the purpose of the example, I am going to use some random number, but those are numbers you can automatically fetch by your project tracking tool. For example, JIRA has a REST api to fetch data about past sprint performance and scheduled releases.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
data = {'completedIssues': [ 7, 9, 10, 11, 12, 14, 21, 17, 22, 23, 17, 19 ] }
df = pd.DataFrame(data=data)
milestone = {
'name': 'Next Big Think',
'milestoneStats': { 'notYetCompletedIssues': 65 },
'sprintsLeftUntilRelease': 4
}
completedIssues = df['completedIssues'].values[-8:]
trials=10000
In this snippet, I initialise all the necessary information for our application.
data: Information about past sprint performance.
milestone: Information about the upcoming milestone. Like how many sprints and how many stories are left.
completedIssues: Since team velocity fluctuates over time, you may want to limit how far into the past to look.
Data from very old sprints may not be representative of current performance.
trials: How many Monte Carlo simulations you would like to run.
Again, even thought, I use static data for this example, it is best to integrate with your project management tool to fetch the data automatically. So that in the end of each sprint, you can fetch the latest information about velocity and also about issues left. From my experience, the scope for a milestone is not set in stone, some stories are going to be dropped and others added all the time.
From data to the delivery random distribution
from scipy.stats import norm
fitting_params_normal = norm.fit(completedIssues)
norm_dist_fitted = norm(*fitting_params_normal)
x = np.linspace(norm_dist_fitted.ppf(0.01), norm_dist_fitted.ppf(0.99), 100)
In this snippet, I use the scipy functionality to automatically compute parameters for the normal random distribution.
In real life, I fitted my data in different distributions like normal, lognormal and exponential.
Normal fitted my data the best. Your mileage may vary, so check for yourself.
Here is how the distribution looks in our example:
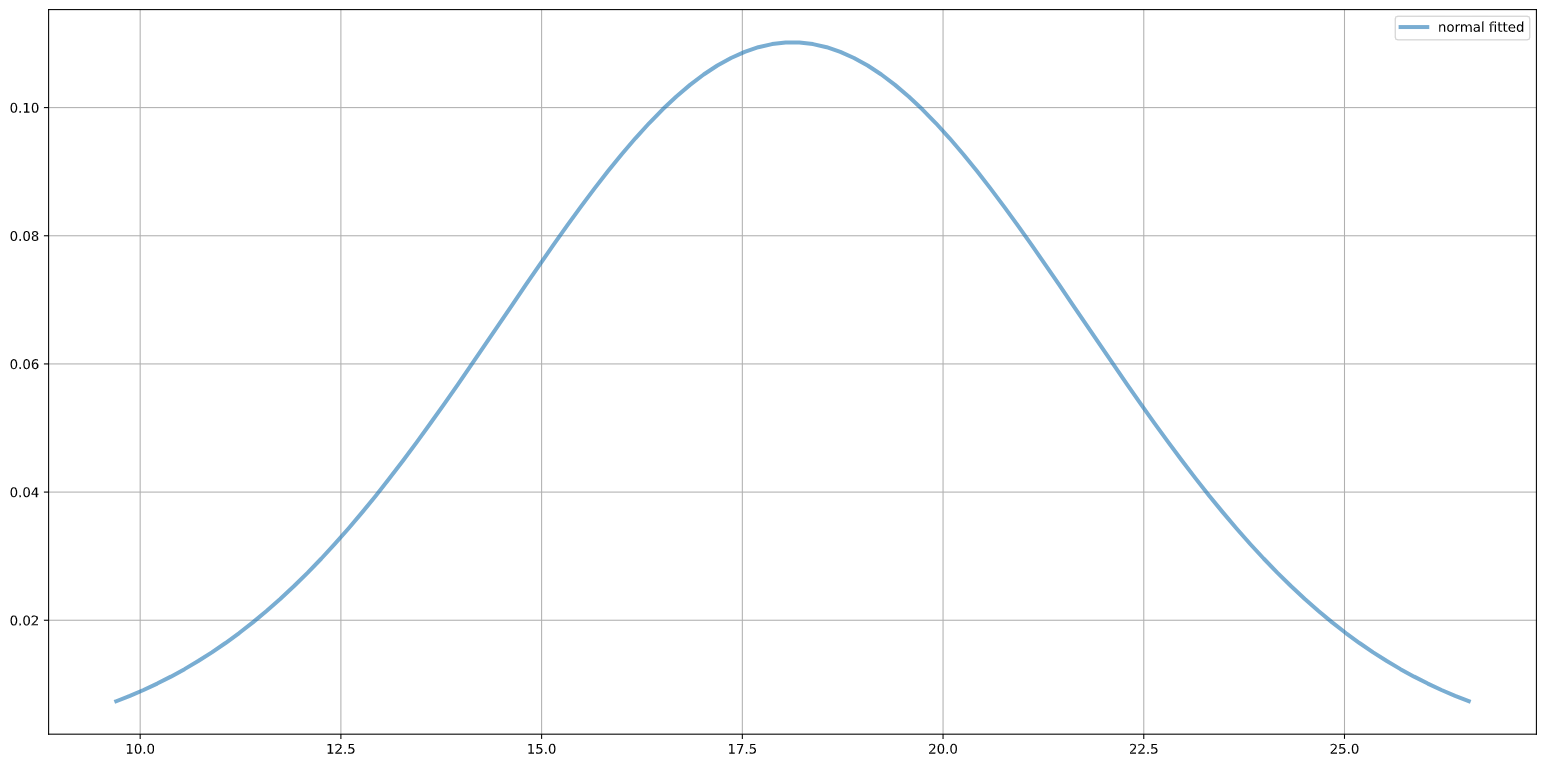
You can read this diagrams as follows. The probability of completing 18 stories is ~12%. The probability of completing 25 stories is 2%, the probability for completing 13 stories is around 4%.
I know that most people like to focus on the mean. But there is so much more information if you look at the whole distribution. Yes, 18 stories is the most likely outcome, but 10 stories can also happen as well as 25 stories and that seems more realistic to me. We all had sprints that did not go that well, because there was something that messed with delivery, like flu season. You need to keep in mind in the future your performance may be lower that your mean performance. By definition, in 50% of your sprints your are going to deliver lower than your mean. Of course, bad sprints and good sprints are going to average out eventually. But, Looking into the next 3 months (6 sprints) is this enough time for things to average out? Maybe not. So, it is better to look into more possible outcomes than just the outcome based on the mean.
Monte Carlo simulation
It is now time to generates velocities for the remaining sprints until the milestone. The velocities are generated randomly based on the random distribution of the past performance. That allows to sample a combination of good and bad sprints.
def analyze_milestone(milestone):
requiredStories = milestone['milestoneStats']['notYetCompletedIssues']
sprintsLeft = milestone['sprintsLeftUntilRelease']
print('name: {}'.format(milestone['name']))
print('required stories: {}, sprints left: {}'.format(requiredStories, sprintsLeft))
futures=[]
for sprint in range(sprintsLeft):
futures.append([ int(i) for i in norm_dist_fitted.rvs(size=trials) ])
combined = list(zip(*futures))
sums = [ sum(i) for i in combined ]
succesfull_sprints = list( filter(lambda s: s >= requiredStories, sums) )
unsuccesfull_sprints = trials - len(succesfull_sprints)
odds = len(succesfull_sprints) / float(trials)
print('succesfull_sprints: {}'.format(len(succesfull_sprints)))
print('odds: {}/{} = {}'.format(len(succesfull_sprints), unsuccesfull_sprints, odds))
print('Success {}% of the times'.format( 100 * len(succesfull_sprints) / trials ))
analyze_milestone(milestone)
That’s the outcome that I got from running the code:
name: Next Big Think
required stories: 65, sprints left: 4
succesfull_sprints: 7933
odds: 7933/2067
Success 79.33% of the times
For this example, the odds look favorable! In 80% of the possible futures we achieved our goal. But is this good enough? Well, it depends on the criticality of the milestone and phase of the project. Stakeholders may find the number uncomfortably low or good enough. Most importantly, this number can be the starting point for a discussion with project management for setting expectations.
Talking about odds
The odds are a powerful tool to communicate confidence. Especially, with people whose job is to do risk management, like project managers.
They allow you to communicate a more complete picture than hard “Yes” or “No” answers, because it is easier to communicate nuances. Odds improve or deteriorate in a continuous and gradual providing transparency and avoiding surprises. Stakeholders are aware of the current likelihood of success. If the odds start to drop towards an uncomfortable level, you can take action early before it becomes a big issue.
Additionally, you can reevaluate at the end of each sprint taking into account the latest velocity and any changes in the remaining scope.
In the end, it’s all about managing risk, but now you have numbers to discuss and keep track of.
Conclusion
In this blog post, I am demonstrating how to automate the Monte Carlo process for sprint planning and forecasting.
You can hook it up with JIRA. Visualise the output in your Grafana dashboard and communicate it with the relevant stakeholders.